Apple iPhone TechTalk 2009 Tricks
 Today I took a day off from work to attend the iPhone Apple Tech Talk 2009 in Toronto. I learned a few cool things and thought I should share it with the two lost developers that may stumble upon this page. I haven't had time to test and verify all of this so as usual: Do your own testing and trust nobody!
Today I took a day off from work to attend the iPhone Apple Tech Talk 2009 in Toronto. I learned a few cool things and thought I should share it with the two lost developers that may stumble upon this page. I haven't had time to test and verify all of this so as usual: Do your own testing and trust nobody!
Talks availables
The agenda was as follows:
| Room A | Room B | Room C | Room D |
|---|---|---|---|
| Effective iPhone App Development - Part 1 | Audio Development Tips for iPhone | iPhone User Interface Design Essentials | Technical Q&A |
| Break | |||
| Effective iPhone App Development - Part 2 | Preparing and Delivering Video for iPhone | Adding In App Purchase to your App | |
| Break | |||
| Working with Core Data | Mastering OpenGL ES for iPhone - Part 1 | Integrating Web Content into iPhone Apps | |
| Break | |||
| Testing and Debugging Your iPhone Application | Mastering OpenGL ES for iPhone - Part 2 | Finding Your Way with Location and Maps | |
| Break | |||
| Maximizing iPhone App Performance | Networking: From Sockets to GameKit | Implementing Push Notification | |
I conveniently stuck to Room B where of course I attended the two openGL sessions, hosted by Allan Schaffer (Graphics & Media Evangelist).
Degenerated GL_TRIANGLE_STRIP trick
Here is a nice trick to fight bandwidth consumption. GL_TRIANGLE_STRIP is the primitive offering the best ratio in terms of faces/vertices. In the following example, 8 vertices allow to generate 6 faces: ABCDEFGH
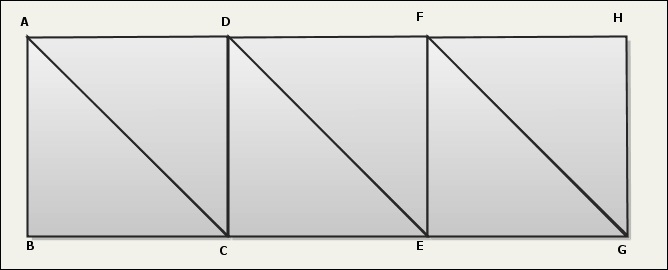
But at first sight, there is no way to draw discontinued shapes. If you want to render something like this:
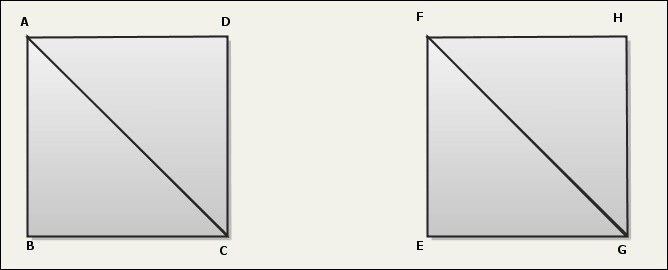
In this situation you may go for:
- 2 drawing calls using GL_TRIANGLE_STRIP : ABCD and EFGH, sending 8 vertices.
- 1 drawing call using GL_TRIANGLES: ABC BDC EFB FGH, sending 12 vertices.
But you can actually have best of both worlds: 1 drawing call using GL_TRIANGLE_STRIP and sending 10 vertices via degenerated faces:
ABCD DE EFGH
The duplicated vertices D and F will result in 4 linefaces that will be discarded by the GPU ! Here is a GLUT example .
Thumb 2.0
Thumb 1.0 is infamous in the world of 3D for not having floating point capability and is hence a pig for ARMv6 architectures. ARMv7 devices now support Thumb 2.0 instruction set which have floating point capability. Smaller instructions are better for the CPU cache, it is hence recommended to enable it on ARMv7 (iPhone 3GS an iTouch 3d generation).
It is not really trivial to build a fat binary which disables Thumb 1.0 for ARMv6 and enables Thumb 2.0 for ARMv7 so here are the steps:
First enable fat binary generation.
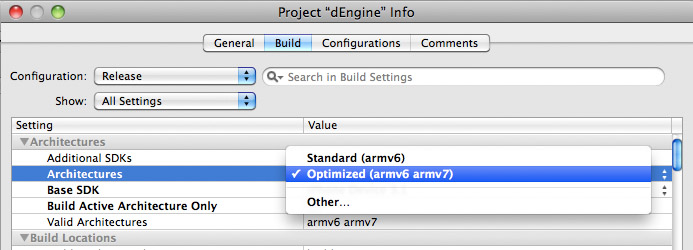
By default there is only one "Thumb" checkbox available!
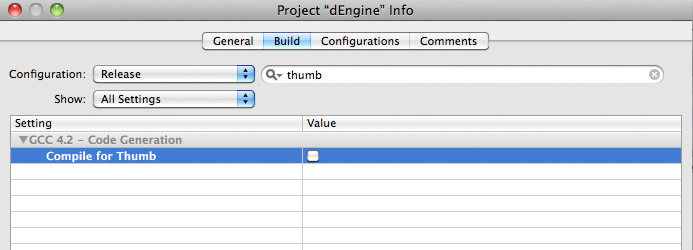
The solution is to use "Add building Setting Condition" at the lower left corner of the build panel.
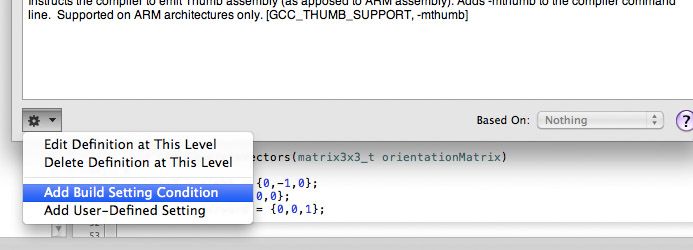
You end up building a fat binary that will be standard ARM 32 bits for armv6 but Thumb 2.0 for armv7.
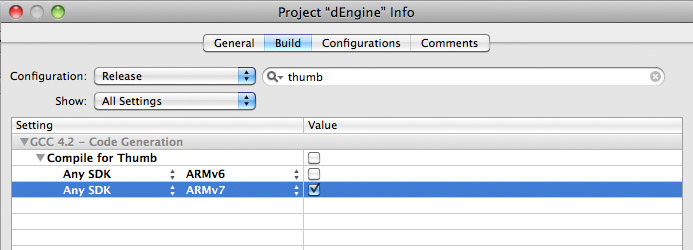
This is "supposed" to be faster on ARMv7.
Bandwidth is not your friend
Allan confirmed that it is actually very hard to get bottlenecked by the GPU's vertices capabilities (not talking about fillrate of course). Most of the time the memory bandwidth will be the bottleneck. So keep on packing, normalizing and compressing guys.
Data alignment
One thing I did not know is that MBX/SGX chips are 4 bytes aligned and every time you send an array of vertices, the driver will copy the data but may repad it to make sure it is properly aligned for the GPU.
//Don't do
typedef struct
{
short pos[3];
short normal[3];
short textUV[2];
}
vertex_t ;
//But instead pre-pad like this:
typedef struct
{
short pos[4];
short normal[4];
short textUV[4];
}
vertex_t ;
It doesn't really make sense to me because whether you declare an array of size 4 with C, the stride you declare later with the GL vertex/normal/texture pointers will hide it from the GPU anyway. I thought that maybe the GPU/driver could perform a batch memcpy if the data were properly aligned but then we increase the bandwidth consumption and the slight improvement is lost.
Again, I will have to do more testing in this regard but I welcome any input on this.
VBO ?
VBO have been a fairly controversial topic in the iPhone world. They were recommended since iPhone 2G even though they provided no speed gain. When the 3GS got released Daniel Pasco from Black Pixel Luminance published some benchmark results which turned out to be very disappointing although Walter Rawdanik from warmi.net had much encouraging results.
During the conference, Apple recommended the usage again and after some testing I found a huge increase in perfs, I recommend to use them along with glMapBuffer.
Mipmapping to reduce bandwidth consumption
Another optimization I never thought of was to use mipMapping. At first you may think that trilinear interpolation will consume more bandwidth but it won't if it's setup to use the nearest mipmap, it will only consume more memory storage.
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST_MIPMAP_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); //or if you want to perform bilinear filtering glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); glTexParameterf(GL_TEXTURE_2D,GL_GENERATE_MIPMAP, GL_TRUE); glTexImage2D(..) ;
This should save some bandwidth.
Tiles and Defered rendering
There were a few great slides reminding us to think in terms of tiles and Deferred Rendering. It's faily expensive to change the layout of the tiles in the middle of a frame so avoid changing the viewport or the spencil / scissor.
RGB -> RGBA
Don't bother too much about saving memory by loading as GL_RGB: These textures are loaded and converted to RGBA with A=1 on the GPU side :( !
There were a few things about texture preloading and warming (some operations on textures are deferred until you use them, drawing one pixel actually gets the texture "ready"), it is recommended not to do the preloading and warming in didFinishLoading delegate (kinda obvious)...because we only have 5 seconds here (I did not know this).
Q&A fail
I had a few questions and was eager to talk to some "much more clever than me" Apple engineers about OpenGL. So I tried to go to the Lab (Room 4) but it seems only Allan knew about OpenGL :/ !
I tried to ask a few questions to Allan between the two conferences. I wanted to know why iPhones ES implementation doesn't support render to depth texture GL_OES_depth_texture and why we did not have floating point (yes, it would help my Variance Shadow Mapping to be decent). They seemed like legitimate questions to me as it appears the hardware is capable. He told me he had no idea and that I should ask an Apple engineer :/.
I also asked him how realistic it was to expect dedicated VRAM on iPHone/iTouch in the next 2 years. He didn't know.
Allan seemed like a sharp guy, I wonder if he dodged it voluntarily or if I just misunderstood what Apple meant by "evangelist" (no sarcasm here).
CADisplayLink is the future
Stop using NSTimer with two threads spaghetti design (as I mentioned in my Doom for Iphone code review), use CADisplayLink from 3.1 and fallback to NSTimer dual thread for earlier versions.
T-Shirt !
Overall the talk was a great time, the catering was excellent (geez didn't know a veggie sandwich could taste that good !!). I even got a cool looking T-shirt "I came, I saw, I Coded" !

On the downside, I did not see ONE girl over there (well I only realized this when my girlfriend asked if they were any), it's a bit sad to go to an event and know that it's going to be a big sausage fest.
Recommended reading
Not really Apple or iPhone related but it's what I've been reading recently: "Linkers and Loaders" by John R. Levine and "The Art of Multiprocessor Programming" by Maurice Herlihy and Nir Shavit : I highly recommend both of them.

|

|
|---|