Quake 2 Source Code Review 4/4
![]()
Quake 2 Source Code Review 1/4 (Intro)
Quake 2 Source Code Review 2/4 (Polymorphism)
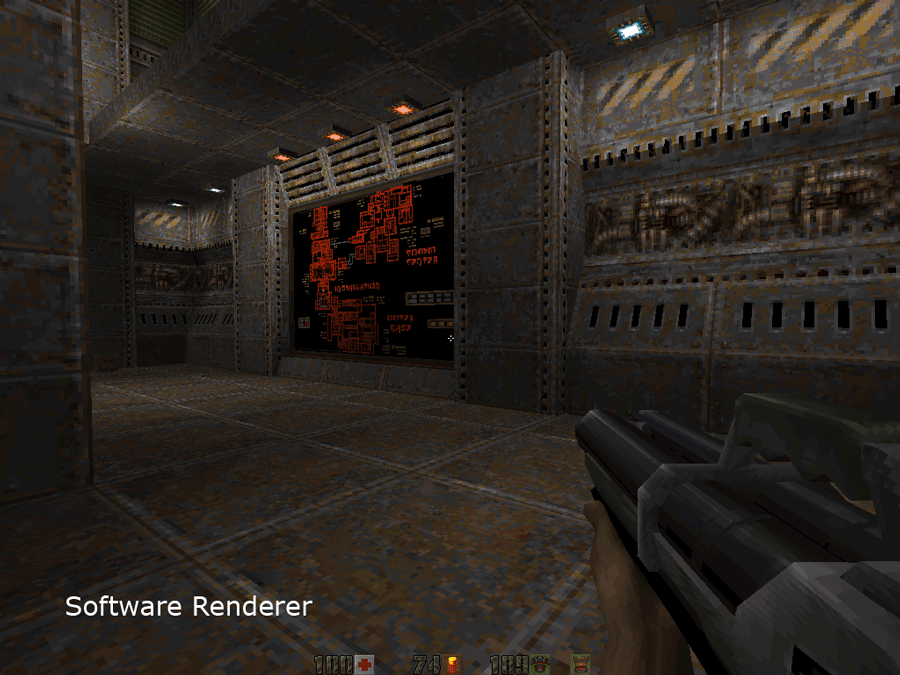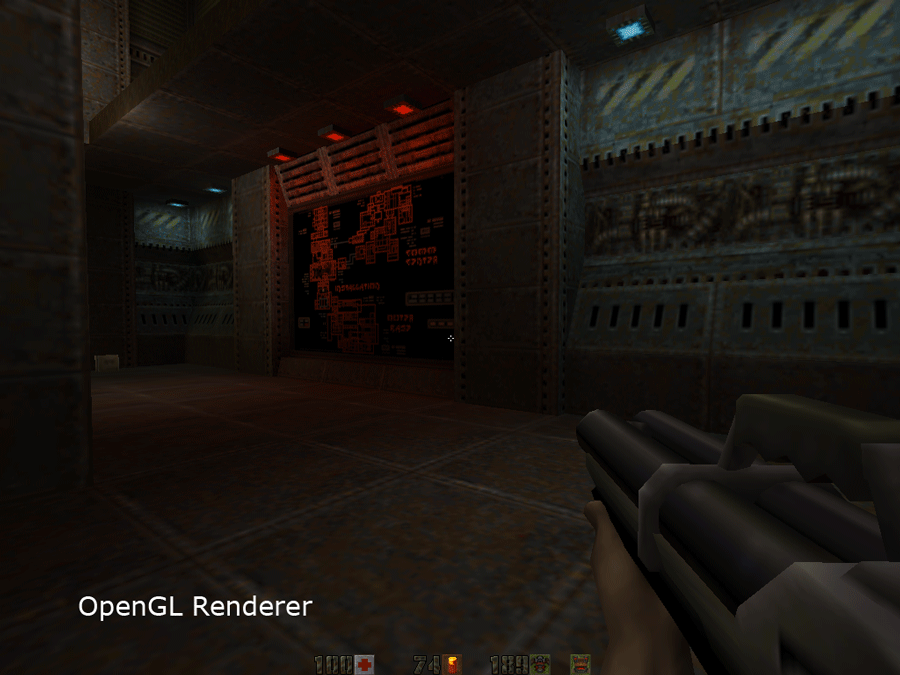
Quake 2 Source Code Review 3/4 (Software Renderer)
Quake 2 Source Code Review 4/4 (OpenGL Renderer)
OpenGL Renderer
 Quake2 was the first engine to ship with native support for hardware accelerated rendition. It demonstrated the
undeniable gain through bilinear texture filtering, multitexturing increase and 24bits color blending.
Quake2 was the first engine to ship with native support for hardware accelerated rendition. It demonstrated the
undeniable gain through bilinear texture filtering, multitexturing increase and 24bits color blending.
From an user perspective the hardware accelerated version provided the following improvements:
- Bilinear filtering
- Colored lighting
- 30% framerate increase at a higher resolution
I can't resist but to quote page 191 of "Masters of Doom" relating John Romero discovering colored lighting for the first time:
When Romero wandered over to id's booth, [...].
He pushed his way through the crowd to see the demo of Quake II. His face filled with yellow light as his jaw slackened. Colored lighting! Romero couldn't believe what he was seeing. The setting was a dungeonlike military level, but when the gamer fired his gun, the yellow blast of the ammunition cast a corresponding yellow glow as it sailed down the walls. It was subtle, but when Romero saw the dynamic colored lighting, it was a moment just like that one back at Softdisk when he saw Dangerous Dave in Copyright Infringement for the first time.
"Holy f*ck," he muttered. Carmack had done it again.
This feature alone had a profound impact on the development of Daikatana.
From a code perspective, the renderer is 50% smaller than the software renderer (see the "Code Statistics" at the end of the page). If this meant less work for the developer
it also mean this implementation is much less subtle and elegant than the software/assembly optimized version:
- The Z-Buffer removed the need for an Active Polygon Stack (this high reliance on a fast Z-buffer resulted in issues during the development of VQuake for V2200 (A few words by one of the dev Stefan Podell (mirror) )
- The raw speed of the rasterizer chips combined to the speed of the Z-Buffer RAM voided the quest for zero overdraw.
- The GPU integrated scanline routine removed the need for a Global Edge Table and an Active Edge Table.
- Lightmap filtering being done on the GPU (and with RGB instead of grayscale): No trace of this on the CPU.
In the end the OpenGL renderer is more of a resource manager than a renderer: sending vertices, uploading
lightmaps atlas on the fly with and setting texture states.
Trivia : A typical frame in Quake2 is 600-900 polygons: A far cry from 2011 millions of polygons in
any game engine.
Code Global Architecture
The rendering phase is very simple and I won't detail it since it is very very similar to the software renderer:
R_RenderView
{
R_PushDlights // Mark polygon affected by dynamic light
R_SetupFrame
R_SetFrustum
R_SetupGL // Setup GL_MODELVIEW and GL_PROJECTION
R_MarkLeaves // Decompress the PVS and mark potentially Visible Polygons
R_DrawWorld // Render Map, cull entire clusters of polygons via BoundingBox Testing
{
}
R_DrawEntitiesOnList // Render entities
R_RenderDlights // Blend dynamic lights
R_DrawParticles // Draw particles
R_DrawAlphaSurfaces // Alpha blend translucent surfaces
R_Flash // Post effects (full screen red for damage, etc...)
}
All the stages are visible in the following video where the engine was "slowed down":
Rendition order:
- World.
- Entities (they are called "alias" in Quake2).
- Particles.
- Translucent surfaces.
- Post-effect full screen.
Most of the code complexity comes from different paths used whether the graphic card supports multitexturing and if batch vertex rendering is enabled: As
an example if multitexturing is supported DrawTextureChains and R_BlendLightmaps do nothing but confuse the reader in the following code sample:
R_DrawWorld
{
//Draw the world, 100% completed if Multitexturing is supported or only pass ONE (color )if not Multitexturing
R_RecursiveWorldNode // Store faces by texture chain in order to avoid texture bind changes
{
//Render all PVS with cluster reject via BBox/Frustrum culling
//Stuff is done here !!
//If visible: render
GL_RenderLightmappedPoly
{
if ( is_dynamic )
{
}
else
{
}
}
}
//Only if no Multlitexturing supported (pass TWO)
DrawTextureChains // Draw all textures chains, this avoid calling bindTexture too many times.
{
for ( i = 0, image=gltextures ; i<numgltextures ; i++,image++)
for ( ; s ; s=s->texturechain)
R_RenderBrushPoly (s)
{
}
}
//Only if no Multlitexturing supported (pass TWO: lightmaps)
R_BlendLightmaps
{
//Render static lightmaps
//Upload and render dynamic lightmaps
if ( gl_dynamic->value )
{
LM_InitBlock
GL_Bind
for ( surf = gl_lms.lightmap_surfaces[0]; surf != 0; surf = surf->lightmapchain )
{
//Check if the block is full.
If full,
upload the block and draw
else
keep on pushing
}
}
}
R_DrawSkyBox
R_DrawTriangleOutlines
}
World rendition
Rendering the map is done in R_DrawWorld. A vertex has five attributes:
- Position.
- Color textureID.
- Color texture coordinates.
- Static Lightmap textureID.
- Static Lightmap texture coordinates.
They are no "Surface" in the OpenGL renderer: color and lightmap are combined on the fly and never cached.
If the graphic card supports multi-texturing only one pass is necessary, specifying both textureID
and textureCoordinates:
- Color texture is bound to OpenGL state GL_TEXTURE0.
- Lightmap texture is bound to OpenGL state GL_TEXTURE1.
- Vertices are sent with color and lightmap texture coordinate.
If the graphic card DO NOT supports multi-texturing two passes are done:
- Blending is disabled.
- Color texture is bound to OpenGL state GL_TEXTURE0.
- Vertices are sent with color texture coordinate.
- Blending is enabled.
- Lightmap texture is bound to OpenGL state GL_TEXTURE0.
- Vertices are sent with lightmap texture coordinate.
Textures management
Since all of the rasterization is done on the GPU, all textures necessary are uploaded to VRAM at the beginning of a level:
- Color textures
- Precalculated lightmaps textures
Using gDEBugger OpenGL debugger it is easy to pock at the GPU memory and get some stats:
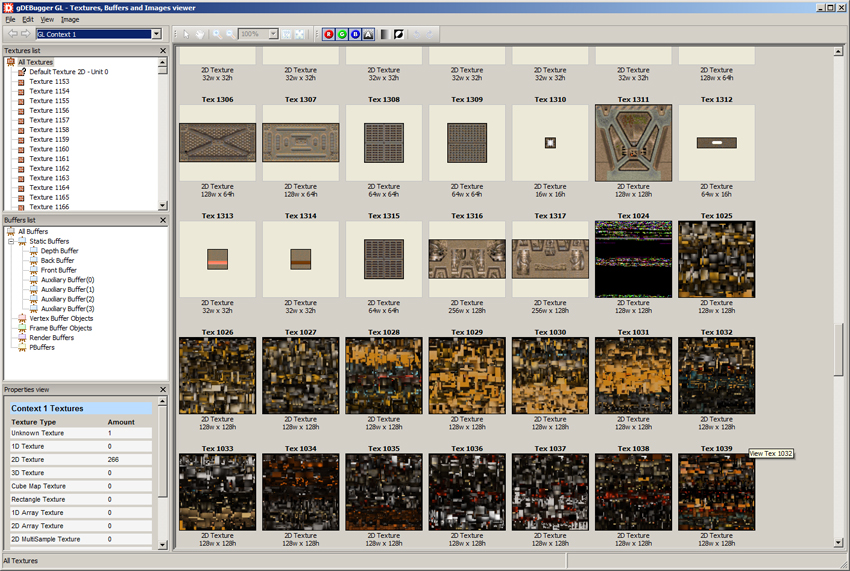
We can see that each color texture as its own textureID. Static lightmaps are uploaded as texture-atlas (called "Block" in quake2) as follow:
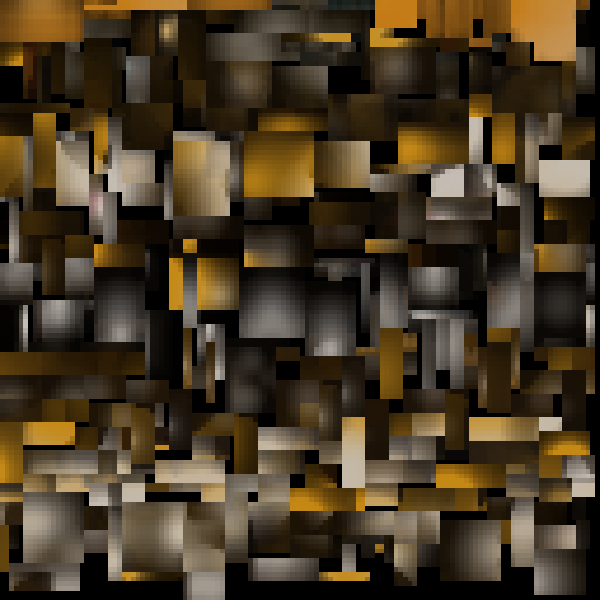
So why are color Texture in their own texture unit while lightmap are aggregated in texture atlas ?
The reason is Texture chain optimizations :
If you want to increase performances with the GPU you should try to avoid changing its state as much as possible.
This is especially true with texture binding (glBindTexture ). Here is a bad example:
for(i=0 ; i < polys.num ; i++)
{
glBindTexture(polys[i].textureColorID , GL_TEXTURE0);
glBindTexture(polys[i].textureLightMapID , GL_TEXTURE1);
RenderPoly(polys[i].vertices);
}
If each polygon has a color texture and a lightmap texture there is very little that can be done but Quake2 organized its lightmap in textureAtlas which are easy to group by id. So polygons are not rendered in the order they are returned from the BSP. Instead they are grouped in texturechains based on the lightmap texture atlas they belong to:
glBindTexture(polys[textureChain[0]].textureLightMapID , GL_TEXTURE1);
for(i=0 ; i < textureChain.num ; i++)
{
glBindTexture(polys[textureChain[i]].textureColorID , GL_TEXTURE0);
RenderPoly(polys[textureChain[i]].vertices);
}
The following video really illustrate the "texture chain" rendition process:
Polygons are not rendered based on distance but rather on what lightmap block they belong to:
Note : In order to achieve consistent translucency only opaque polygons were falling in the texture chain sink, translucent poly are still rendered far to near.
Dynamic lighting
At the very beginning of the rendition phase, all polygons are marked in order to show is they are subject to
dynamic lighting (R_PushDlights). If so, the precalculated static lightmap is not used but instead
a new lightmap is generated combining the static lightmap and adding the light projected on the polygon plan (R_BuildLightMap).
Since a lightmap maximum dimension is 17x17 the dynamic lightmap generation phase is not
too costy..but uploading the change to the GPU with qglTexSubImage2D is VERY slow.
A 128x128 lightmap block is dedicated to store all dynamic lightmaps: id=1024. See "Lightmap management"
to see how all dynamic lightmap were combined in a texture atlas on the fly.

Note : If the dynamic lightmap is full, a rendition batch is performed. The rover keeping track of allocated space is reset and
dynamic lightmap generation resumes.
Lightmap managment
As stated earlier, there is no concept of "surface" in the OpenGL version: Lightmap and color texture were combined on the fly and NOT cached.
Even though static lightmap are uploaded to the VRAM they are still kept in RAM: If a polygon is subject to a dynamic light, a new lightmap is generated
combining the static lightmap with the light projected onto it. The dynamic lightmap is then uploaded to textureId=1024 and used for texturing.
Texture atlas were actually called "Block" in Quake2, all 128x128 texels and handled with three functions:
LM_InitBlock: Reset the block memory consumption tracking.LM_UploadBlock: Upload or Update a texture content.LM_AllocBlock: Find a suitable location to store a lightmap.
The next video illustrate how lightmaps are combined into a Block. The engine is playing a little game of tetris here, scanning
from left to right all the way an remembering where the lightmap fits entirely at the highest location in the image.
The algorithm is noteworthy: A rover (
int gl_lms.allocated[BLOCK_WIDTH]) keeps tracks of what height has been consumed for each column of pixels all width long.
// "best" variable would have been better called "bestHeight"
// "best2" vatiable would have been MUST better called "tentativeHeight"
static qboolean LM_AllocBlock (int w, int h, int *x, int *y)
{
int i, j;
int best, best2;
//FCS: At what height store the new lightmap
best = BLOCK_HEIGHT;
for (i=0 ; i<BLOCK_WIDTH-w ; i++)
{
best2 = 0;
for (j=0 ; j<w ; j++)
{
if (gl_lms.allocated[i+j] >= best)
break;
if (gl_lms.allocated[i+j] > best2)
best2 = gl_lms.allocated[i+j];
}
if (j == w)
{ // this is a valid spot
*x = i;
*y = best = best2;
}
}
if (best + h > BLOCK_HEIGHT)
return false;
for (i=0 ; i<w ; i++)
gl_lms.allocated[*x + i] = best + h;
return true;
}
Note: The "rover" design pattern is very elegant and is also used in the software surface caching memory system.
Fillrate and rendition passes.
As you can see in the next video, the overdraw could be quite substantial:
In the worse case scenario a pixel could be written 3-4 times (not counting overdraw):
- World: 1-2 passes (depending on multitexturing).
- Particles blending: 1 pass.
- Post-effect blending: 1 pass.
GL_LINEAR
Bilinear filtering was good when used on the color texture but it really shone when filtering the lightmaps:
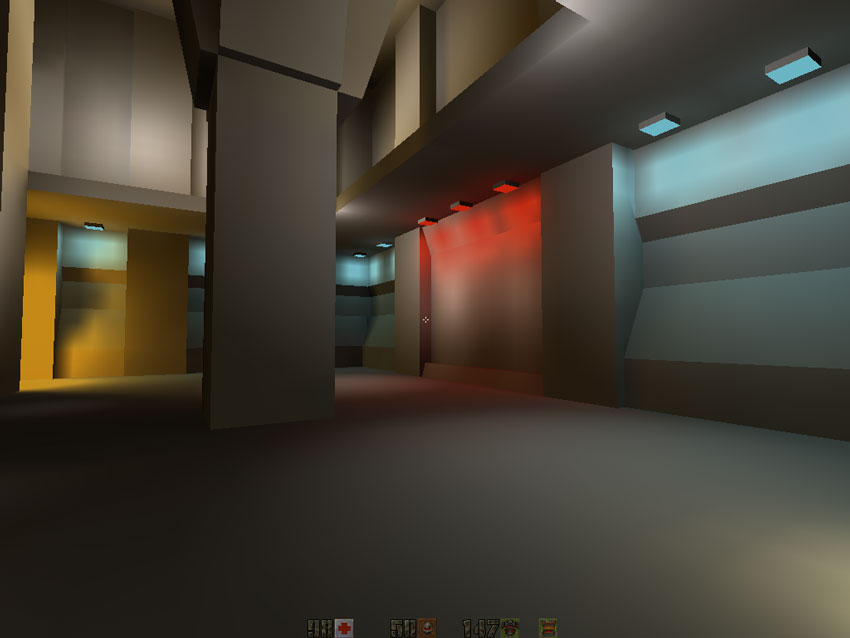
All together:
Entities rendition
Entities are rendered via batches: vertices, texture coordinate and color array pointers are setup and everything is sent via a
glArrayElement.
Before rendition, all entities vertices are lerped for smooth animation (only keyframes were used in Quake1).
The lighting model is Gouraud: the color array is hijacked by Quake2 to store lighting value.
Before rendition the lighting value is calculated for each vertex and stored in the color array. This color value
is interpolated on the GPU for a nice Gouraud result.
R_DrawEntitiesOnList
{
if (!r_drawentities->value)
return;
// Non-transparent entities
for (i=0 ; i < r_newrefdef.num_entities ; i++)
{
R_DrawAliasModel
{
R_LightPoint /// Determine color of the light to apply to the entire model
GL_Bind(skin->texnum); //Bind entitiy texture
GL_DrawAliasFrameLerp() //Draw
{
GL_LerpVerts //LERP interpolation of all vertices
// Calculate light for each vertices, store it in colorArray
for ( i = 0; i < paliashdr->num_xyz; i++ )
{
}
qglLockArraysEXT
qglArrayElement // DRAW !!
qglUnlockArraysEXT
}
}
}
// Transparent entities
for (i=0 ; i < r_newrefdef.num_entities ; i++)
{
R_DrawAliasModel
{
[...]
}
}
}
Backface culling is performed on the GPU (well since T&L was still done on CPU at the time I guess we can say it was done in the driver stage).
Note : In order to speed things up the light direction used for calculation is always the same (
{-1, 0, 0} ) but it does not show in the engine. The color of the light
is accurate and is picked via the current poly the entity is resting on.This can be seen very well in the next screen shot were the light and shadow are all in the same direction even though the light source are inconsistent.
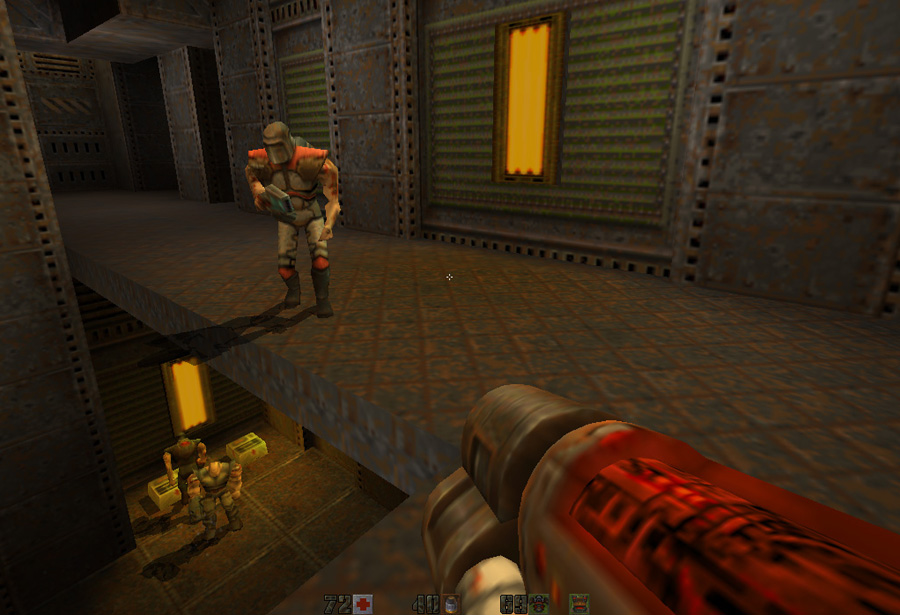
Note: Of course it is not always perfect, shadow extend over the void and faces overwrite each other, causing different level of shadow but still pretty impressive for 1997.
More on shadows :
Unknown to a lot of people, Quake2 was able to calculate crude shadows for entities. Although disabled by default, this feature can be activated via the command
gl_shadows 1.The shadow always go in the same direction (not based on closest light), faces are projected on the entity level plane. In the code,
R_DrawAliasModel generate a shadevector that is used in GL_DrawAliasShadow to perform the face projection on the entity level plan.Entities rendition lighting: The quantization trick
You may think that the low number of polygons in an alias would have allowed to calculate normal and dot product normal/light in real time....but NO.
All dotproduct are precalculated and stored in float r_avertexnormal_dots[SHADEDOT_QUANT][256], where SHADEDOT_QUANT=16.
Quantization is used: The light direction is always the same: {-1,0,0}.
Only 16 different set of normals are calculated, depending on the Y orientation of the model.
Once one of the 16 orientation is selected the dotproduct are precomputed for 256 different normals. A normal in MD2 model format is ALWAYS an index in the precomputed array.
Any combination of X,Y,Z normal falls in one of the 256 directions.
With all those limitations, all dotproduct are looked up from the 16x256 r_avertexnormal_dots. Since normal index cannot interpolated in the animation process the closest normal index from a keyframe is used.
More to read about this: http://www.quake-1.com/docs/quakesrc.org/97.html
mirror) .
Old Old OpenGL...
Where is my glGenTextures ?!:
Nowaday an openGL developer request a textureID from the GPU with glGenTextures. Quake2 doesn't bother
doing this and unilateraly decide of an ID. So color textures start at 0, the dynamic lightmap texture is always 1024 and
the static lighmap are 1025 up to 1036.
Infamous Immediate mode :
Vertices data are passed to the video card via ImmediateMode. Two function calls per vertex glVertex3fv
and glTexCoord2f for the world rendition (because polygons were culled individually there was no way
to batch them).
Batch rendition is performed for aliasModels (enemies,players) with glEnableClientState( GL_VERTEX_ARRAY ).
Vertices are sent to glVertexPointer and glColorPointer is used to pass the lighting value
calculated on the CPU.
Multitexturing :
The code is complicated by trying to accommodate hardwares with and without support for the brand new...multitexturing.
No usage of GL_LIGHTING :
Since all lighting calculations were performed on CPU (texture generation for the world and vertex light value for entities) there are no traces of GL_LIGHTING
in the code.
Since OpenGL 1.0 was doing Gourant shading anyway (by interpolating color across vertex) instead of Phong (where normal are interpolated for a real "per-pixel-lighting")
to use GL_LIGHTING would have not looked good for the world since it would have required to create vertices on the fly.
It "could" have been done for entities but at the cost of also sending vertices normal vectors . It seems this was ruled against and hence
lighting value calculation is performed on the CPU. Lighting value are passed in the color array, values are interpolated on the GPU for a Gouraud result.
Fullscreen Post-effects
The palette based software renderer did an elegant full palette colord blending with an optionnal Gamma correction with lookup table but the OpenGL version doesn't care about this and you can
see it is again using a bruteforce approach in R_Flash:
Problem : You want the screen to be a little big more red ?
Solution : Just draw a gigantic red GL_QUAD with alpha blending enabled all over the screen. Done.
Note : The Server was driving the Client just like the software renderer: If any part of the Server
wanted to have a post-effect full screen color blended it just had to set the RGBA float player_state_t.blend[4] variable. The variable value
then transited over the network thanks to the quake2 kernel and was sent to the renderer DLL.
Profiling
Visual Studio 2008 Team's profiler is dreamy, here are what came up with Quake2 OpenGL:
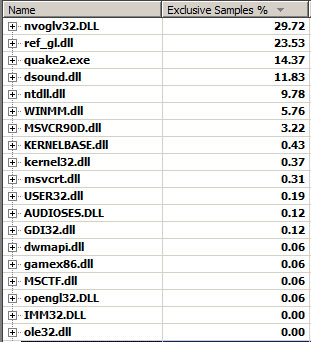
This is not a surprise: Most of the time is spent in the NVidia and Win32's OpenGL driver (nvoglv32.dll and opengl32.dll)
for a total of 30%. Rendition is done on the GPU but A LOT OF TIME is wasted via the immediate mode's many method calls and also to copy the data from RAM to VRAM.
Next comes the renderer module (ref_gl.dll 23%) and the quake2 kernel (quake2.exe 15%).
Even though the engine is relying massively on malloc, we can see that the time spent there is almost inexistant (MSVCR90D.dll
and msvcrt.dll).
Also non-existant, the time spent in the game logic (gamex86.dll).
A surprising amount of time is spent in the directX's sound library (dsound.dll) for 12% of cumulated time.
If we take a closer look to Quake2 OpenGL renderer dll:
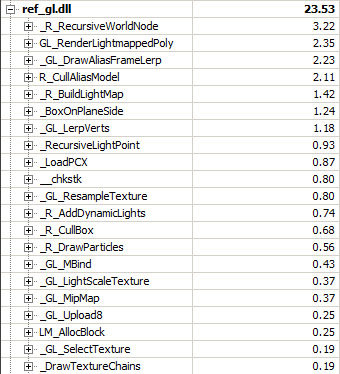
- Most of the time is spent rendering the world (
R_RecurseiveWorldNode). - Close second is to render enemies (alias models): (
GL_DrawAliasFrameLerp2.5%). The cost is quite high even though all dot product are precalculated as seen before. - Lightmap generation (when a dynamic light prevent usage of the static precalculated lightmap) also represent 2.5% (
GL_RenderLightMappedPoly).
Overall the OpenGL dll is well balanced, there are NO obvious bottlenecks.
Code Statistics
Code analysis by Cloc shows a total of 7,265 lines of code.
$ cloc ref_gl
17 text files.
17 unique files.
1 file ignored.
http://cloc.sourceforge.net v 1.53 T=1.0 s (16.0 files/s, 10602.0 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C 9 1522 1403 6201
C/C++ Header 6 237 175 1062
Teamcenter def 1 0 0 2
-------------------------------------------------------------------------------
SUM: 16 1759 1578 7265
-------------------------------------------------------------------------------
The difference is striking when comparing to the software renderer: 50% less code, NO assembly optimization for a result that is 30% faster and features colored lighting and bilinear filtering. It is easy to understand why id Software did not bother shipping an software renderer in Quake3.