Quake 2 Source Code Review 3/4
![]() Quake2 software render is the biggest, most complicated and hence most exciting module to explore.
Quake2 software render is the biggest, most complicated and hence most exciting module to explore.
Quake 2 Source Code Review 1/4 (Intro)
Quake 2 Source Code Review 2/4 (Polymorphism)
Quake 2 Source Code Review 3/4 (Software Renderer)
Quake 2 Source Code Review 4/4 (OpenGL Renderer)
Software Renderer
 From disk to pixel there are no hidden mecanisms here:
Everything has been carefully coded and optimized by hand. It is the last of its kind, marking the end of an era before the industry moved to hardware accelerated only.
From disk to pixel there are no hidden mecanisms here:
Everything has been carefully coded and optimized by hand. It is the last of its kind, marking the end of an era before the industry moved to hardware accelerated only.
The fundamental thing that differentiate the software and OpenGL renderer is the usage of a 256 colors palette system instead of the usual 24 bits RGB true color system found everywhere nowaday:
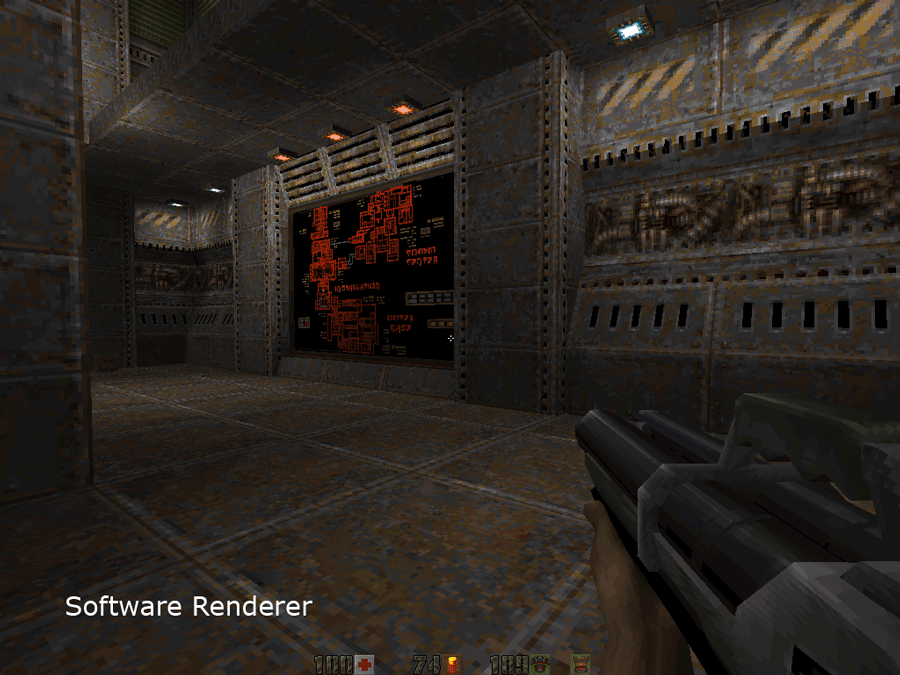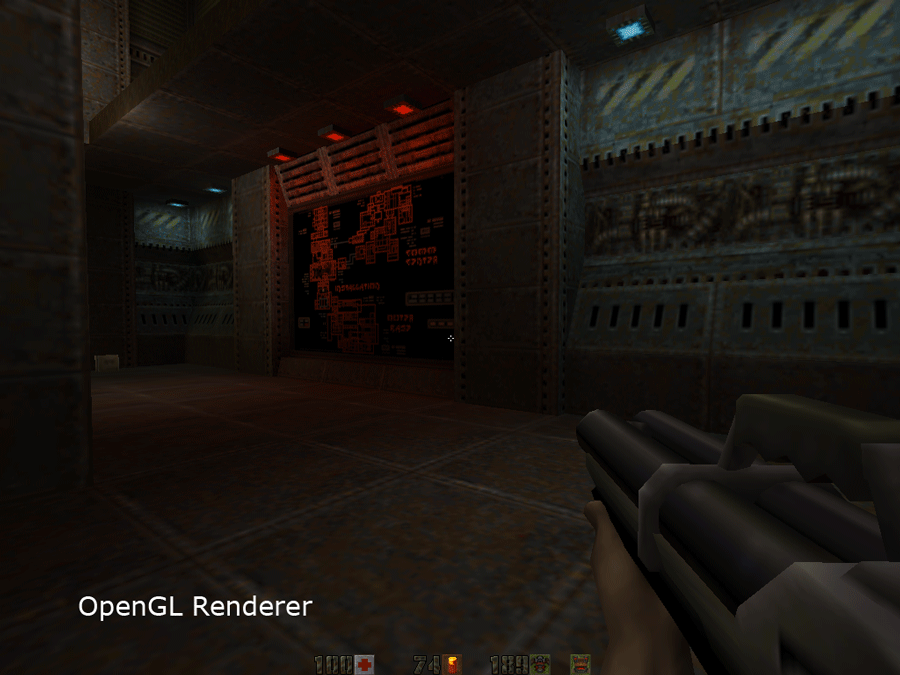
If we compare the hardware accelerated and the software renderer, the two most obvious differences are:
- Absence of colored lighting
- Absence of bilinear filtering
But except for those the engine managed to do amazing things via very clever arrangements of the palette that I detail later in this page:
- Color gradients (64 values) fast selection.
- Post-effect full screen color blending.
- Per-pixel translucency.
The Quake2 palette is loaded first from the PAK archive file pics/colormap.pcx:

Note : Black is at 0, White at 15, Green at 208 Red at the bottom left is 240 (transparent is 255).
The first thing done is to use those 256 colors and re-arrange them as seen in pics/colormap.pcx:

This 256x320 re-arrangement is used as lookup table and is incredibly clever, unlocking so many many sweat things:
- 64 lines to fake color gradients: The first line is made of the 256 colors from the palette "unrolled". The 63 remaining entries in each column represent vertically
a gradient of the initial color, faked with the other 255 colors available. This enable a very simple and fast gradient selection mechanism:
- First select a color from the palette within [0,255] (this comes from the color texture).
- Then add x*256, where x is within [0,63] to get a darkening version of the color initially selected (this comes from the lightmap texture).
- The rest of the image is made of 16x16 squares that enable palette based pixel blending. You can clearly see all the squares made of a Source Color, a Destination Color and intermediate colors inbetween. That's how water translucency is done in the game. As and example the top left square blends between white and black.
Trivia : Quake2's software renderer was initially supposed to be RGB based instead of palette based thank to
MMX technology as John Carmack announced it after the release of Quake1 in this video (at 10m17s mark):
MMX is a SIMD technology that would have allowed to work on the three channels of RGB at the cost of one channel hence enabling blending with an acceptable CPU consumption. My guess is that it was scrapped for two reasons:
- MMX enabled Pentium were rare in 1997, the software renderer was supposed to be the configuration for low budget machines.
- Transfering an RGB (16 bits or 32 bits per pixel) instead of a palette based (8 bits per pixel) was consuming too much bandwidth and an acceptable framerate could be be achieved.
Global architecture
Now that the big limitation is set (palette), we can go on the global architecture of the renderer. The philosophy is to rely heavily on what the
Pentium is good at (floating point calculation) in order to minimize the impact of its weakness: Bus speed that affects writing pixels to memory. Most
of the rendering path focuses on achieving ZERO overdraw.
In essence the software rendering path is identical to Quake 1's software renderer relying heavily
on the BSP to traverse the map and the PVS (Potentially visible set) to build the set of polygons to render.
Three different things are rendered each frames:
- The map: Using a scan-line bsp based coherence algorithm (detailed later).
- Entities: Either as "sprite"(windows) or "alias"(players,enemies) using a plain scan-line algorithm.
- Particles.
Note : If you are unfamiliar with those "old" algorithms, I highly recommend to read Chapter 3.6 and 15.6 from Computer graphics: principles and practice By James D. Foley. You can also find a lot
of information in chapters 59 to 70 in Graphics programming black book by Michael Abrash.
Here it is a pseudo-highlevel-code:
- Render the map
- Walk the pre-processed BSP to determine in which cluster we are.
- Query the PVS database for this particular cluster: Retrieve and decompress the PVS.
- Using the PVS bit vector: Mark as visible every polygon belonging to a cluster designated as Potentially Visible.
- Walk the BSP again, this time check if visible cluster are affected by any dynamic light. If so, mark them with the light's id number.
- Now we have a list of what is potentially visible with lighting information:
- Use the BSP again, walk it near to far:
- Test against view frustrum and project all polygons on screen: Build a Global Edge Table.
- Render each face's surface (surface=texture+lightmap) to a cache in RAM.
- Insert surface pointer on the surface stack (later used for coherency).
- Using the surface stack and the Global Edge Table, generate an Active Edge Table and render the screen line by line from top to bottom. Use the surface cache in RAM as texture. Write spans to offscreen buffer and also populate a Z-Buffer.
- Render the entities, use the Z-Buffer to determine which part of the entity is visible.
- Render translucent textures, use a cool palette trick to calculate the translucent palette indices per pixel.
- Render particles.
- Perform post-effect (damage blend full screen with a red color).
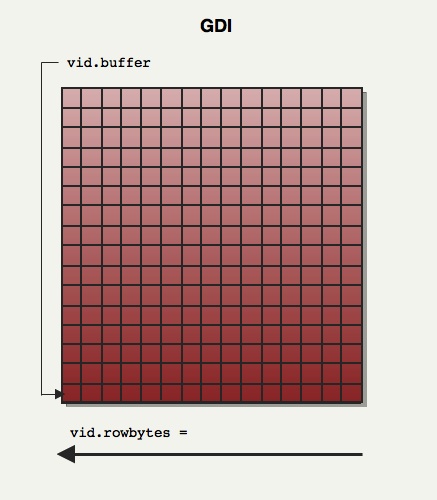
Screen rendition : Palette indices are written to an offscreen buffer. Depending if the engine runs fullscreen or windowed, DirectDraw or GDI are respectively used. When the offscreen framebuffer has been completed, it is blitted to the videocard backbuffer (GDI=>
rw_dib.c DirectDraw=>rw_ddraw.c) using either WinGDI.h's BitBlt
or ddraw.h's BltFast.
DirectDraw Vs GDI
The kind of things programmers hard to deal with around 1997 is just saddening: See John Carmack's funny comment in the source code:
// can be negative for stupid dibs
If Quake2 was running fullscreen with DirectDraw it had to draw the offscreen buffer from
top to bottom:
the way it would appear on the screen. But if it was running in windowed mode with Window's GDI, it had to draw the offscreen buffer in a DIB buffer.....VERTICALLY FLIPPED because
most Graphic vendors drivers were blitting the DIB image from RAM to VRAM in flipmode (you have to wonder if the 'I' in GDI really stands for "Independent").
So the offscreen framebuffer navigation had to be abstracted via a structure and values were initialized
differently to abstract the difference. This is a crude way to do polymorphism in C ;).
typedef struct
{
pixel_t *buffer; // The offscreen framebuffer
pixel_t *colormap; // The color gradient palette: 256 * VID_GRADES size
pixel_t *alphamap; // The translucency palette : 256 * 256 translucency map
int rowbytes; // may be > width if displayed in a window
// can be negative for stupid dibs
int width;
int height;
} viddef_t;
viddef_t vid ;
Depending on the way the framebuffer had to be drawn, vid.buffer was initialized to either the first pixel of:
- First line for DirectDraw
- Last line for WinGDI/DBI Surface
In order to navigate up or down, vid.rowbytes was either initialized to vid.width or -vid.width.

Now to navigate whether we had to draw normally or vertically flipped doesn't matter:
// First pixel of first row
byte* pixel = vid.buffer + vid.rowbytes * 0;
// First pixel of last row
pixel = vid.buffer + vid.rowbytes * (vid.height-1);
// First pixel of row i (row numbering starts at 0)
pixel = vid.buffer + vid.rowbytes * i;
// Clear the framebuffer to black
memset(vid.buffer,0,vid.height*vid.height) ; // <-- This will work in fullScreen DirectDraw mode
// but crash in windowed mode :( !
This trick allowed the entire rendition pipeline to never worry about the underlying blitter and I think it is pretty awesome.
Map preprocessing
Before digging in the code further it is important to understand two important databases generated during map preprocessing:
- Binary Space Partioning/ Potentialy Visible Set.
- Radiosity based lightmap texture.
BSP Slicing, PVS Generation
I invite you to read more about Binary Space Partitioning:
- Wikipedia.
- The Idea of BSP Trees by Michael Abrash.
- Compiling BSP Trees by Michael Abrash.
- The old bible ASCII style article.
Just like in Quake1, Quake2 maps are heavily pre-processed : The volume is sliced recursively as in the following drawing:
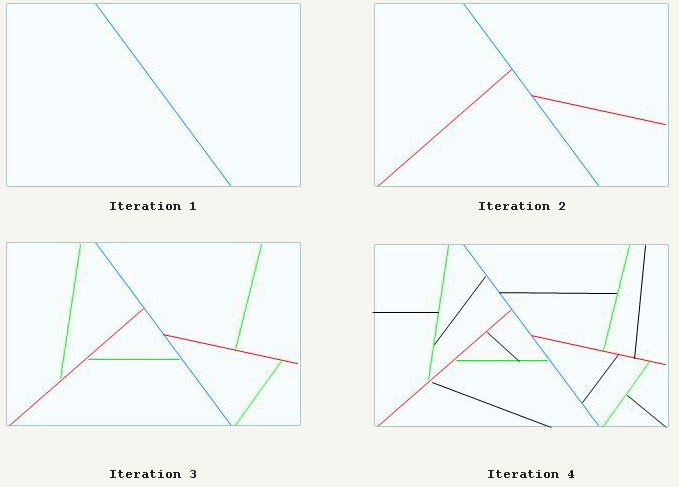
In the end, the map had been sliced in convex 3D spaces (called clusters) and just like in Doom and Quake1 it can be used to sort all polygons around Near to Far or Far to Near.
The great addition is the PVS (Potentially Visible Set), a set of bit vector (one entry per cluster) that can be seen as a database that can be queried to retrieve what clusters are Potentially Visible from any cluster.
This database is huge (5MB) but efficiently compressed to a few hundred of KB so it can fit nicely in RAM.
Note : The Run-length compression used to shrink the PVS can skip only 0x00s, this process is detailed later.
Radiosity
Just like in Quake1 the map's light impact were precalculated and stored in textures called lightmaps . Contrary to Quake1, Quake2 used radiosity and colored light during the precalculation. The lightmaps were then stored in the PAK archive and used at runtime:
A few words from one of the creator: Michael Abrash in "Black Book of Programming" (Chapitre: "Quake: a post-mortem and a glimpse into the
future"):
The most interesting graphics change is in the preprocessing, where John has added support for radiosity lighting...
Quake 2 levels are taking up to an hour to process.
(Note, however, that that includes BSPing, PVS calculations, and radiosity lighting, which I'll discuss later.)
If you don't know what radiosity illumination is, read this extremely well illustrated
article (mirror)
: it is pure gold .
Here is the first level, textured with the radiosity texture only: Unfortunately the gorgeous colored RGB had to be resampled to grayscale for the software renderer (more about this later).
The low resolution of the lightmap is striking here but since they are bilinear filtered (yes even in
the software renderer) the end result combined to a color texture is very good.
Trivia :The lightmaps could be any size from 2x2 up to 17x17 (contrary to the stated
maxsize of 16 in flipcode's article
(mirror)) and did not have to be square.
Code architecture
Most of the software renderer code is in the method R_RenderFrame. Here is a summary but for a more complete breakdown
check out my raw notes.
R_SetupFrame: Retrieve the current viewing location by walking the BSP (call toMod_PointInLeaf), store the viewpoint clusterID inr_viewcluster.R_MarkLeaves: Using the current view cluster (r_viewcluster), retrieve and decompress the PVS. Use the PVS to mark all faces visible.R_PushDlights: Use the BSP again walking faces near to far and if the face is marked as visible, check if it is affected by a light.R_EdgeDrawing: Map RenditionR_RenderWorld: Walk the BSP Near to Far- Project every visible polygons in screen space: Build a Global Edge Table.
- Also Push a surface proxy for each visible surface on the surface stack (This is done for coherence purpose).
R_ScanEdges: Render the map scanline per scanline from top to bottom. For each line:R_InsertNewEdges: Use the Global Edge Table to initalized the Active Edge Table, use it as a set of event.(*pdrawfunc)(): Generate spans but don't write to offscreen buffer, instead insert the spans in a span stack buffer. Reason is detailled later.D_DrawSurfaces: If the span stack buffer is full, render all spans to the offscreen buffer and reset the span stack.
R_DrawEntitiesOnList: Render entities that are not BModel (A bmodel is an element of the map). Render Sprites and AliasModels (players,enemies, ammos)...R_DrawAlphaSurfaces: Use a cool trick to perform per pixel blendingR_CalcPalette: Perform post effect such as color blending (damage, item pick-up)
R_RenderFrame
{
R_SetupFrame // Set pdrawfunc function pointer, depending if we are rendering for GDI or DirectDraw
{
Mod_PointInLeaf // Determine what is the current view cluster (walking the BSP tree) and store it in r_viewcluster
}
R_MarkLeaves // Using the current view cluster (r_viewcluster), retrieve and decompress
// the PVS (Potentially Visible Set)
R_PushDlights // For each dlight_t* passed via r_newrefdef.dlights, mark polygons affected by a light.
// Build the Global Edge Table and render it via the Active Edge Table
R_EdgeDrawing // Render the map
{
R_BeginEdgeFrame // Set function pointer pdrawfunc used later in this function
R_RenderWorld // Build the Global Edget Table
// Also populate the surface stack and count # surfaces to render (surf_max is the max)
R_DrawBEntitiesOnList// I seriously have no idea what this thing is doing.
R_ScanEdges // Use the Global Edge Table to maintin the Active Edge Table: Draw the world as scanlines
// Write the Z-Buffer (but no read)
{
for (iv=r_refdef.vrect.y ; iv<bottom ; iv++)
{
R_InsertNewEdges // Update AET with GET event
(*pdrawfunc)(); //Generate spans
D_DrawSurfaces //Draw stuff on screen
}
// Flush span buffer
R_InsertNewEdges // Update AET with GET event
(*pdrawfunc)(); //Generate spans
D_DrawSurfaces //Draw stuff on screen
}
}
R_DrawEntitiesOnList // Draw enemies, barrel etc...
// Use Z-Buffer in read mode only.
R_DrawParticles // Duh !
R_DrawAlphaSurfaces // Perform pixel palette blending ia the pics/colormap.pcx lower part lookup table.
R_SetLightLevel // Save off light value for server to look at (BIG HACK!)
R_CalcPalette // Modify the palette (when taking hit or pickup item) so all colors are modified
}
R_SetupFrame: BSP Manipulation
Binary Space Partition walking is done everywhere in the code and it's a powerful constant speed mechanism to sort polygons near to far or far to near. The key is to
understand the cplane_t structure:
typedef struct cplane_s
{
vec3_t normal;
float dist;
} cplane_t;
In order to calculate the distance or a point from a splitting plan in a node, we only have to inject its coordinates in the plane equation:
int d = DotProduct (p,plane->normal) - plane->dist;
With the sign of d we know if we are in front or behind the plane and sorting can be done. It is a process that is used from Doom to Quake3.
R_MarkLeaves: Runlength PVS decompression
The way I understood PVS decompression in my Quake 1 Engine code review was plain wrong. It is not the distance between 1 bits that is encoded but the number of 0x00 bytes to write. Only 0x00 is runlength compressed in the PVS: Upon reading the compressed stream:
- if a non-zero byte is read from the compressed PVS, is is written as is in the decompressed version.
- If a 0x00 byte is read from the compressed PVS, the next byte indicates how many 0x00 bytes follow.
This means the PVS is compressed by compacting subsequent 0x00 bytes. Other bytes are left uncompressed.
byte *Mod_DecompressVis (byte *in, model_t *model)
{
static byte decompressed[MAX_MAP_LEAFS/8]; // A leaf = 1bit so only 65536 / 8 = 8,192 bytes
// are needed to store a fully decompressed PVS.
int c;
byte *out;
int row;
row = (model->vis->numclusters+7)>>3;
out = decompressed;
do
{
if (*in) // This is a non null byte, write it as is and continue to the next compressed byte.
{
*out++ = *in++;
continue;
}
c = in[1]; // We did not "continue" so this is a null byte: Read the next byte (in[1]) and write as
in += 2; // many byte as requested in the uncompressed PVS.
while (c)
{
*out++ = 0;
c--;
}
} while (out - decompressed < row);
return decompressed;
}
The compression scheme allows to compress at most 255 bytes containing 0x00 (255*8 leafs), a new zero must be issued with a number after to skip an other 255 bytes if necessary. Skipping 511 bytes (511*8 leafs) hence consumes 4 bytes: 0 - 255 - 0 - 255
Example:
// Example of a system with 80 leafs, represented on 10 bytes: visible=1, invisible=0
Binary Uncompressed PVS
0000 0000 0000 0000 0000 0000 0000 0000 0011 1100 1011 1111 0000 0000 0000 0000 0000 0000 0000 0000
Hexadecimal Uncompressed PVS
0x00 0x00 0x00 0x00 0x39 0xBF 0x00 0x00 0x00 0x00
// !! COMPRESSION !!
Binary Compressed PVS
0000 0000 0000 1000 0011 1100 1011 1111 0000 0000 0000 1000
Hexadecimal Compressed PVS
0x00 0x04 0x39 0xBF 0x00 0x04
Keep in mind that contrary to Quake 1, the PVS in Quake 2 contains not leaf IDs but cluster IDs. In order to reduce compilation time, designers were allowed to mark some walls are "detail" which were not accounted as blocking the view. As a result, the PVS contains clusterID and some leave share the same cluster ID.
Once the PVS of the current cluster has been decompressed, every single face belonging to a cluster designated as visible by the PVS is marked as visible too:
Q : With a decompressed PVS, given a cluster ID i, how you test if it is visible ?
A : Bit AND between the i/8's byte of the PVS and 1 << (i % 8)
char isVisible(byte* pvs, int i)
{
// i>>3 = i/8
// i&7 = i%8
return pvs[i>>3] & (1<<(i&7))
}
Just like in Quake1, there is a nice trick used to mark a polygon as "visible": Instead of using
a flag and have to reset all of them at the beginning of each frame, an int was used. Every beginning of frame
a framecounter r_visframecount was increased by one in R_MarkLeaves. After decompressing the PVS, all zones
are marked visible by setting its visframe field to the current value of r_visframecount.
Later in the code, node/cluster visibility is always tested as follow:
if (node->visframe == r_visframecount)
{
// Node is visible
}
R_PushDlights: Dynamic lighting
For each active dynamic light lightID the BSP walked recursively starting from the light's position. Calculate the distance
light <-> Cluster and if the light intensity if greater than the distance from the cluster, mark all surfaces in the
cluster as affected by this light ID.
Note : Surfaces are marked via two fields:
dlightframeis a flagintworking in the same way clusters are marked for visibily (instead of reseting all flags, a global variabler_dlightframecountis increased each frame. In order to be affected by a light:r_dlightframecountmust be equal tosurf.dlightframe.dlightbitsis anintbitvector used to store the different light's array index affecting this face.
Once the flag is raised the lights affecting the surface are encoded in an
int, used as a bitvector. Hence at maximum 32 lights can affect a surface.
R_EdgeDrawing: Map rendition
R_EdgeDrawing is the kraken of the software renderer, the most complex and hardest to understand. The key to
get it is to see the main data structure:
A stack of surf_t (acting as proxy to m_surface_t) allocated on the CPU stack.
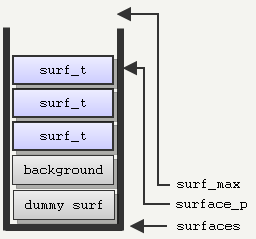
//Surface stack system
surf_t *surfaces ; // Surface stack array
surf_t *surface_p ; // Surface stack top
surf_t *surf_max ; // Surface stack upper limit
// surfaces are generated in back to front order by the bsp, so if a surf
// pointer is greater than another one, it should be drawn in front
// surfaces[1] is the background, and is used as the active surface stack
Note: The first element in surfaces is the dummy surface
Note: The second element in surfaces is the background surface
This stack is populated when walking the BSP near to far. Each visible polygon is inserted in the stack as a surface
proxy. Later when walking an Active Edge Table to generate a line of the screen, it allows to see very fast which
polygon is in front of all the others by simply comparing the address in memory (the lower in the stack = the closer
to the Point of View). This is how "coherence" is done for the scan-line conversion algorithm.
Note : Each entry in the stack also features a linked list (called Texture Chain), pointing to elements in the span buffer stack (detailed just after).
Spans are stored in a buffer and drawn from the texture chain in order to group span per texture and maximize the CPU pre-caching buffer.
The stack is initialized at the very beginning of R_EdgeDrawing:
void R_EdgeDrawing (void)
{
// Total size: 64KB
surf_t lsurfs[NUMSTACKSURFACES +((CACHE_SIZE - 1) / sizeof(surf_t)) + 1];
surfaces = (surf_t *) (((long)&lsurfs[0] + CACHE_SIZE - 1) & ~(CACHE_SIZE - 1));
surf_max = &surfaces[r_cnumsurfs];
// surface 0 doesn't really exist; it's just a dummy because index 0
// is used to indicate no edge attached to surface
surfaces--;
R_SurfacePatch ();
R_BeginEdgeFrame (); // surface_p = &surfaces[2];
// background is surface 1,
// surface 0 is a dummy
R_RenderWorld
{
R_RenderFace
}
R_DrawBEntitiesOnList
R_ScanEdges // Write the Z-Buffer (but no read)
{
for (iv=r_refdef.vrect.y ; iv<bottom ; iv++)
{
R_InsertNewEdges // Update AET with GET event
(*pdrawfunc)(); //Generate spans
D_DrawSurfaces //Draw stuff on screen
}
// Flush span buffer
R_InsertNewEdges // Update AET with GET event
(*pdrawfunc)(); //Generate spans
D_DrawSurfaces //Draw stuff on screen
}
}
Here are the details:
R_BeginEdgeFrame: Cleanup the Global Edge Table from last frame.R_RenderWorld: Walk the BSP (note that it does NOT render anything to the screen):- Every surface deemed visible is added on the stack with a
surf_tproxy. - Project all polygon's vertices in screen space and populate the Global Edge Table.
- Also generate the 1/Z value for each vertices so the Z-Buffer can be generated with spans.
- Every surface deemed visible is added on the stack with a
R_DrawBEntitiesOnList: I seriously have no idea what this thing is doing.R_ScanEdges: Combine all information build so far to render the map:- Initialize the Active Edge Table.
- Initialize the span buffer (also a stack):
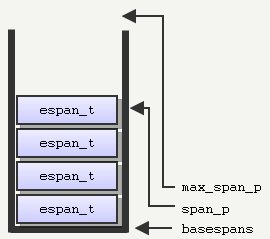
// Span stack system espan_t *span_p; //Current top of the span stack pointer espan_t *max_span_p; //Max span_p beyond this, the stack overflows // Note: The span stack (basespans) allocated on the CPU stack void R_ScanEdges (void) { int iv, bottom; byte basespans[MAXSPANS*sizeof(espan_t)+CACHE_SIZE]; ... }- Start the scanline algorithm, from the top of the screen to the bottom.
- For each line:
- Update the Active Edge Table with the Global Edge Table.
- Run the Active Edge Table on the entire line:
- Determine visible polygon using the address on the surface stack.
- Emit a span in the span buffer.
- If span buffer is full: Draw all the spans and reset the span stack.
- Check if there is anything remaining in the span buffer, if yes: Draw all the spans and reset the span stack.
R_EdgeDrawing video
In the following video the engine was running at 1024x768. It was also slowed down and a special cvar sw_drawflat 1 was enabled to render polygons without textures but with different colors:
There are soooo many things to notice in this video:
- Screen is generated top to bottom this is a typical scanline algorithm.
- Horizontal span of pixels are not written as generated. This is done to optimized the Pentium pre-fetching cache: Spans are grouped by textureId with a mechanism called "texture chains". Spans are stored in a buffer. When the buffer is full: spans are drawn with texture chains in ONE batch.
- The moment when the span buffer is full and a rendition batch is triggered is obvious since the polygon rendering stops around the 50th pixels line .
- Spans are generated top to bottom but they are drawn bottom to top: Since spans are inserted in a texture chain at the top of the listed list, spans are drawn in the reverse order they were produced.
- The last batch is covering 40% of the screen while the first one covered 10%. It is because they are far less polygon there, the spans are not cuts and they cover much more area.
- OMG ZERO OVERDRAW during the solid world rendition step .
Precalculated Radiosity: Lightmaps
Unfortunately the nice 24bits RGB lightmaps had to be resampled to 6bits grayscale (selecting the brightest channel between R, G and B) in order to fit the palette limitation:
What is stored in the PAK archive (24bits):
After loading from disk, and resampling to 6bits:
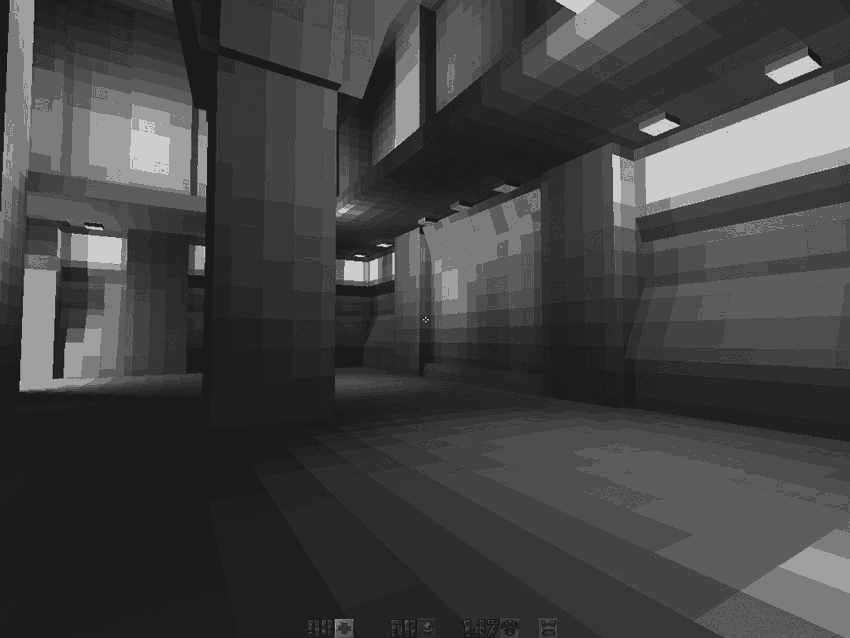
Now all together: The face's texture give the color in the range [0,255]. This value indexes a color in the palette from pics/colormap.pcx:

The lightmaps are filtered: we end up with a value [0,63].

Now using the upper part of pics/colormap.pcx the engine can select the right palette entry: Using the texture entry value as X coordinate and the luminance*63 as Y coordinate for the final result:

Et voila:

I personally think it is awesome to manage to fake 64 gradients of 256 colors....will only 256 colors :) !
Surface subsystem
According to the previous screenshots it is obvious that surface generation is the most CPU intensive part of Quake2 (this is confirmed by the profiler results seen later in this page). Two mechanisms make surface generation affordable in terms of speed and memory consumption:
- Mipmapping
- Caching
Surface subsystem: Mipmapping
When a polygon is projected in screen space, its distance 1/Z is generated. The closest vertex is used to see which mipmap level should be used.
Here is an example of a lightmap and how it is filtered according to the mipmap level:


Here is a mini project I worked on in order to test Quake2's bilinear filtering quality on random images: 
Following are the result of a test done on a 13x15 texels lightmap:
 |
 |
| Mimpap level 3: Block are 2x2 texels. | Mimpap level 2: Block are 4x4 texels. |
 |
 |
| Mimpap level 1: Block are 8x8 texels. | Mimpap level 0: Block are 16x16 texels. |
The key to understand the filtering is that everything is based on the polygons world space dimension ( width and height are called
extent):
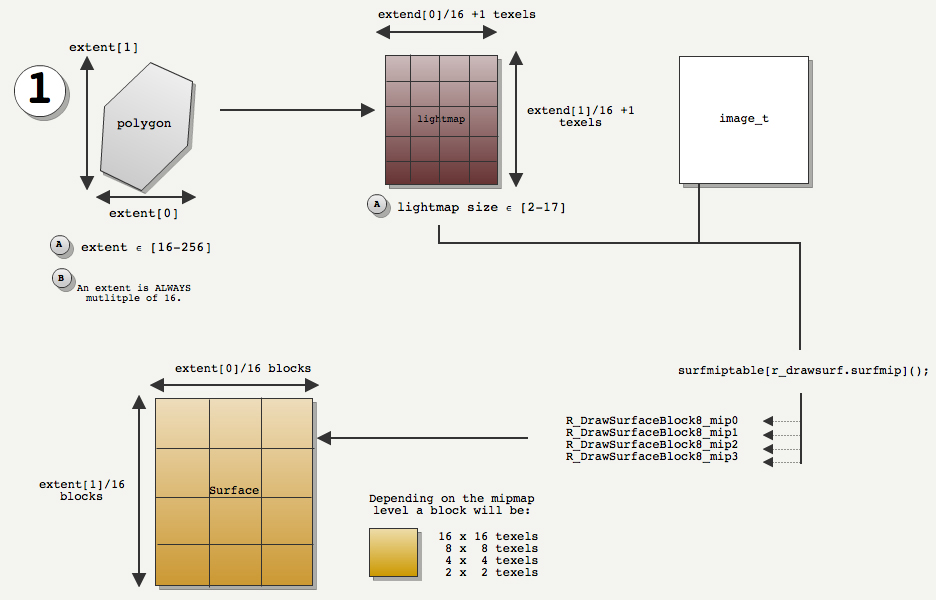
- The Quake2 preprocessor made sure a polygon dimensions (X or Y) were less or equal to 256 and also a multiple of 16.
- From a world space dimension of a polygon we can deduce:
- The lightmap dimension (in texels): LmpDim = PolyDim / 16 + 1
- The Surface dimension (in blocks): SurDim = LmpDim -1 = PolyDim / 16
In the following drawing the polygon dimension are (3,4), the lightmap is (4,5) texels and the surface degenerated will ALWAYS be (3,4) blocks. The mipmap levels decides the texels dimensions of a block and hence the overall size of the surface in texels.
All this is done in R_DrawSurface. The mipmap level is selected thanks to an array of function pointer (surfmiptable) selecting the right rasterizing function:
static void (*surfmiptable[4])(void) = {
R_DrawSurfaceBlock8_mip0,
R_DrawSurfaceBlock8_mip1,
R_DrawSurfaceBlock8_mip2,
R_DrawSurfaceBlock8_mip3
};
R_DrawSurface
{
pblockdrawer = surfmiptable[r_drawsurf.surfmip];
for (u=0 ; u<r_numhblocks; u++)
(*pblockdrawer)();
}
In the following altered engine you can see three levels of mipmap: 0 in grey, 1 in yellow and 2 in red:

Filtering is done by block, when generating the surface's block[i][j], the filterer would use the lightmap values: lightmap[i][j],lightmap[i+1][j],lightmap[i][j+1] and lightmap[i+1][j+1]:
essentially using the four texels located directly at the coordinate and the three ones below and to the right. Note that is is not doing weighted interpolation but rather linear interpolation
vertically first and the interpolating horizontally again on the values generated. In short, it is working exactly as the wikipedia article about bilinear filtering is describing it.
All together now :
 |
 |
| Original Lightmap 13x15 texels. | Mimpap level 0 filtered (16x16 blocks)=192x224 texels. |

Surface subsystem: Caching
Even though the engine relied massively on malloc and free for memory management it still used its own memory
manager for surface caching. A block of memory was initialized as soon as the rendition resolution was known:
size = SURFCACHE_SIZE_AT_320X240;
pix = vid.width*vid.height;
if (pix > 64000)
size += (pix-64000)*3;
size = (size + 8191) & ~8191;
sc_base = (surfcache_t *)malloc(size);
sc_rover = sc_base;
A rover sc_rover was placed at the beginning on the block to keep track of what had been consumed so far. When the rover reached the end of the memory
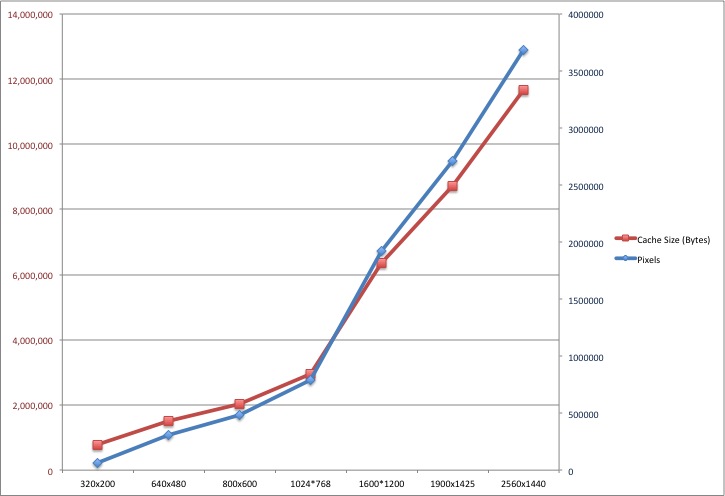
is was wrapping around, essentially recycling old surfaces. The amount of memory reserved can be seen in this graph:
Here is the way a new chunk of memory is allocated from the block:
memLoc = (int)&((surfcache_t *)0)->data[size]; // Skipping size+ enough space for the memory chunk header.
memLoc = (memLoc + 3) & ~3; /FCS: Round up to a multiple of 4
sc_rover = (surfcache_t *)( (byte *)new + size);
Notice: Fast cache alignment trick (May have to go in memory system)
Notice: A header is placed on top of the requested amount of memory. Very bizarre line, using a NULL (((surfcache_t *)0)) pointer (but it is ok since it is not deferenced).
Perspective Projection of the Poor ?
Several posts on the internet suggest that Quake2 use the "perspective projection of the poor" with a simple formula and no
homogeneous coordinates or matrices (following code from R_ClipAndDrawPoly):
XscreenSpace = X / Z * XScale
YscreenSpace = Y / Z * YScale
Where XScale and YScale are determined by the Field Of View and the screen aspect ratio.
This perspective projection is actually equivalent to what happens in OpenGL during the GL_PROJECTION + W divide phase:
Perspective Projection:
=======================
Eye coordinate vector
| X
| Y
| Z
| 1
--------------------------------------------------
Perspective Projection Matrix |
|
XScale 0 0 0 | XClip
0 YScale 0 0 | YClip
0 0 V1 V2 | ZClip
0 0 -1 0 | WClip
Clip Coordinates:
================ XClip = X * XScale
YClip = Y * YScale
ZClip = /
WClip = -Z
NDC Coordinate with W Divide:
=========
XNDC = XClip/WClip = X * XScale / -Z
YNDC = YClip/WClip = Y * YScale / -Z
First naive proof: Compare superposed screenshots. If we look at the code Projection of the poor ? NOPE !!
R_DrawEntitiesOnList: Sprites and Alias Entities
At this point in the rendition process, the map has been rendered to screen:
The engine also generated a 16bits z-buffer (that was written to but never read) in the process:

Note : We notice that close value are "brighter" (which is contrary of OpenGL where closer is "darker"). This is because 1/Z instead of Z is stored in the Z-buffer.
The 16bits z-buffer is stored starting at pointer d_pzbuffer :
short *d_pzbuffer;
As stated previously 1/Z is stored using the direct application of the formula described in Michael Absrash's article "Consider the Alternatives: Quake's Hidden-Surface Removal".
It can be found in D_DrawZSpans:
zi = d_ziorigin + dv*d_zistepv + du*d_zistepu;
If you are interested in the mathematical proof that you can indeed interpolate 1/Z, here is paper by
Kok-Lim Low:

The z-buffer outputed during the map rendition phase is now used as input so entities can be clipped properly properly.
A few things about animated entities (players and enemies):
- Quake1 draws only keyframes but now all vertices are LERPed (
R_AliasSetUpLerpData) for smooth animation. - Quake1 used to render distance entities as "BLOB": An inaccurate but very fast rendition method. This is now gone and Quake2 renders entities normally after BoudingBox testing and front facing testing with cross product.
In terms of lighting:
- No shadow are every drawn.
- Polygon are gouraud shaded with a hardcoded light direction (
{-1, 0, 0}fromR_AliasSetupLighting). - The lighting intensity is based on the surface's light intensity it is currently positioned on.

Translucency in R_DrawAlphaSurfaces
Translucency had to be done with palette indexes. I must have wrote this 10 times
on this page but it only express how incredibly AWESOME I think it is.
Translucent polygon are rendered as follow:
- Projection of all vertices on screen space.
- Left Edge, Right Edge determination. Slop based system.
- If the surface is not warping (animated water), rendition to cache system in RAM.
The trick is achieved using the second part of the
pics/colormap.pcx image as lookup to blend
a source pixel from the surface cache with a destination pixel (offscreen framebuffer):The source input generates the X coordinate and the destination the Y coordinate. Resulting pixel is written to the offscreen framebuffer:

Next is an animation illustrating "Before" and "After" a per pixel palette blending:
R_CalcPalette: Post effect operations and Gamma correction
Not only the engine was capable of "per pixel palette blending" and "palette based color gradient selection",
it could also modify its entire palette in order to indicate damages or items pick up:

If any "thinker" in the game DLL on the server side wanted to have a color blended at the end of the rendition process it only had to set the value in the RGBA variable float player_state_t.blend[4] for any player in the game.
This value was transmitted over the network, copied in refdef.blend[4]'s and passed to the renderer DLL (what a transit!). Upon detection it was blended with each 256s RGB entries in the palette index. After gamma corection, the palette was then re-uploaded to the graphic card.
R_CalcPalette in r_main.c :
// newcolor = color * alpha + blend * (1 - alpha)
alpha = r_newrefdef.blend[3];
premult[0] = r_newrefdef.blend[0]*alpha*255;
premult[1] = r_newrefdef.blend[1]*alpha*255;
premult[2] = r_newrefdef.blend[2]*alpha*255;
one_minus_alpha = (1.0 - alpha);
in = (byte *)d_8to24table;
out = palette[0];
for (i=0 ; i<256 ; i++, in+=4, out+=4)
for (j=0 ; j<3 ; j++)
v = premult[j] + one_minus_alpha * in[j];
Trivia : After the palette is altered via the method previously mentionned it has to be gamma corrected (in R_GammaCorrectAndSetPalette):
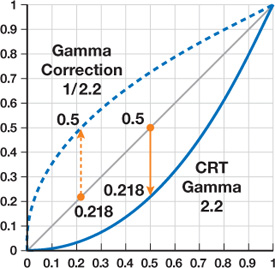
Gamma correction is an expensive operation, notably involving a call to pow and a division....and has to be perform for each R,G and B channel of a color entry !:
int newValue = 255 * pow ( (value+0.5)/255.5 , gammaFactor ) + 0.5;
In total it is 3 calls to pow, 3 divisions, 6 additions and 3 multiplication for each 256 entries in the palette index: That's A LOT.
But since the input set is limited to 8 bits per channel, the full correction can be precomputed and cached in a tiny array of 256 entries:
void Draw_BuildGammaTable (void)
{
int i, inf;
float g;
g = vid_gamma->value;
if (g == 1.0)
{
for (i=0 ; i<256 ; i++)
sw_state.gammatable[i] = i;
return;
}
for (i=0 ; i<256 ; i++)
{
inf = 255 * pow ( (i+0.5)/255.5 , g ) + 0.5;
if (inf < 0)
inf = 0;
if (inf > 255)
inf = 255;
sw_state.gammatable[i] = inf;
}
}
Hence a lookup table is used to do the trick (sw_state.gammatable) and greatly speedup the gamma correction process.
void R_GammaCorrectAndSetPalette( const unsigned char *palette )
{
int i;
for ( i = 0; i < 256; i++ )
{
sw_state.currentpalette[i*4+0] = sw_state.gammatable[palette[i*4+0]];
sw_state.currentpalette[i*4+1] = sw_state.gammatable[palette[i*4+1]];
sw_state.currentpalette[i*4+2] = sw_state.gammatable[palette[i*4+2]];
}
SWimp_SetPalette( sw_state.currentpalette );
}
Note : You may think that LCD flat screen don't have the same gamma issue as old CRT...except that they are usually
designed to mimic CRT behavior :/ !
Code Statistics
A little bit of Code analysis by Cloc in order to close with the software renderer shows a total of 14,874 lines of code for this module. It is a little bit more than 10% of the total line count but this is not representative of the overall effort since several design were tested before settling with this one.
$ cloc ref_soft/
39 text files.
38 unique files.
4 files ignored.
http://cloc.sourceforge.net v 1.53 T=0.5 s (68.0 files/s, 44420.0 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C 17 2459 2341 8976
Assembly 9 1020 880 3849
C/C++ Header 7 343 293 2047
Teamcenter def 1 0 0 2
-------------------------------------------------------------------------------
SUM: 34 3822 3514 14874
-------------------------------------------------------------------------------
The assembly optimization in the nine r_*.asm accounts for 25% of the codebase, that a pretty impressive proportion and I think quite representative
of the effort required by the software renderer:
Most of the rasterization routine were hand optimized for x86 processor by Michael Abrash. Most of the Pentium optimization discussed in his
"Graphics Programming Black Book" can be seen in action in those files.
Trivia : Some method names are the same in the book and Quake2 code (i.e: ScanEdges).
Profiling
 I tried different profilers, all of them integrated to Visual Studio 2008:
I tried different profilers, all of them integrated to Visual Studio 2008:
- AMD Code Analysis:
- Intel' VTune Amplifier XE 2011
- Visual Studio Team Profiler
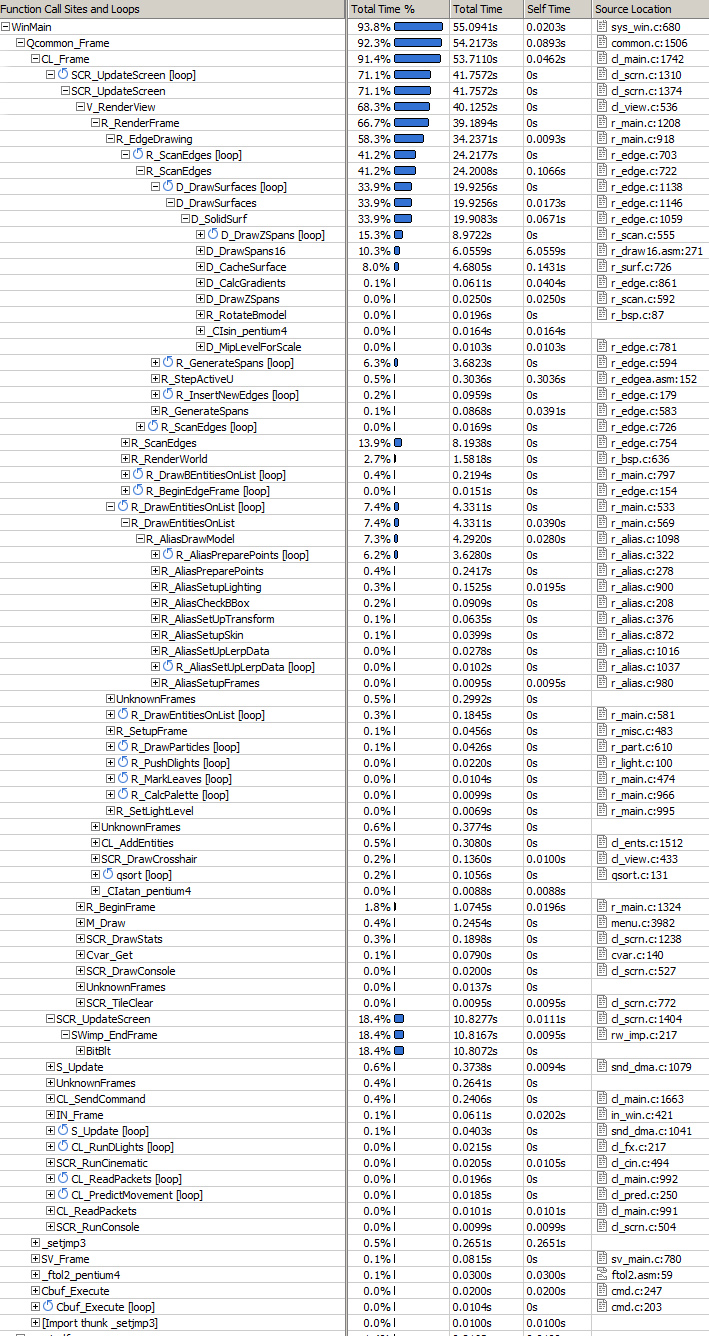
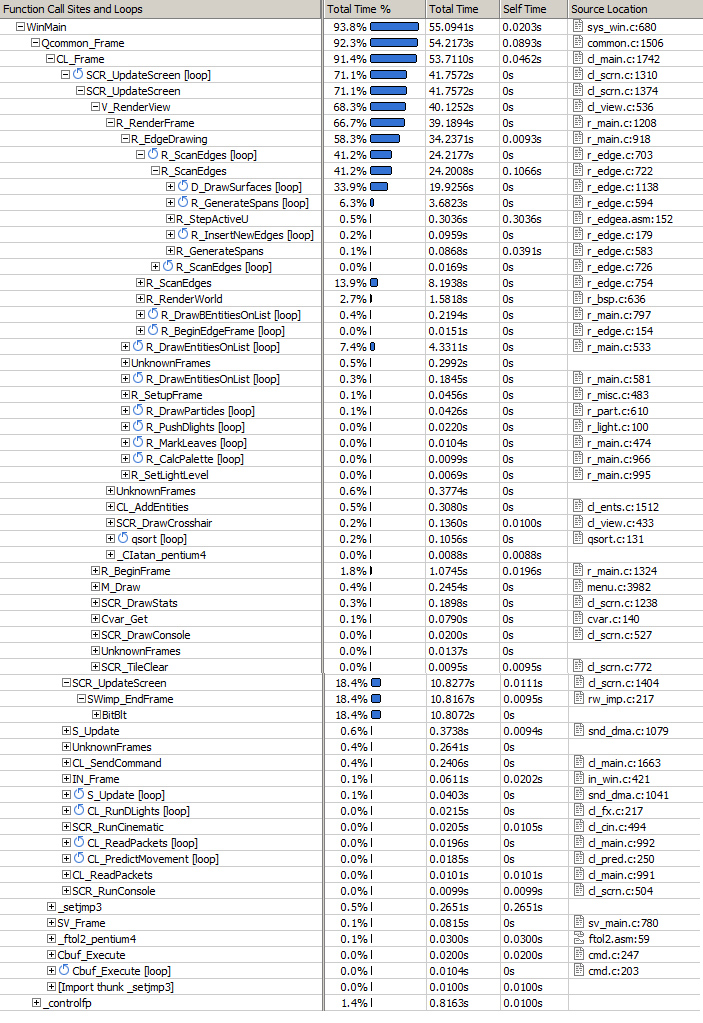
BitBlit) but the two other missed it.Instrumentation failed on both Intel and AMD's profiler (I am not masochist enough to investigate why) but the Profiler from VS 2008 Team edition succeeded...although I would not recommend it: The game ran at 3 frames per seconds and a 20 seconds session took 1h to analyse !
Profiling with VS 2008 Team edition :
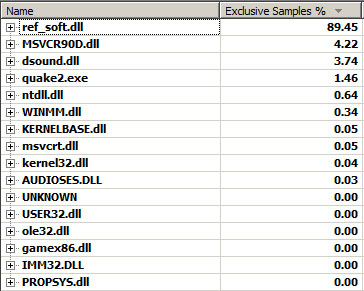
Result is self-explanatory:
- Software rendition cost is overwhelming: 89% is spent in the DLL.
- Game logic is barely noticeable : 0%.
- A surprising lot of time is spent in the DirectX sound DLL.
- More time is spent in
libcthan in the quake.exe kernel.
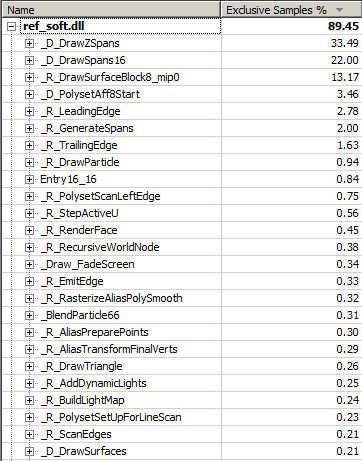
Looking closer at the ref_soft.dll time consumption:
- As mentioned earlier in this chapter "Writing byte to memory cost a lot":
- Huge cost (33%) associated to building the Z-Buffer (
D_DrawZSpans). - Huge cost (22%) associated to writing spans to offscreen buffer (
D_DrawZSpans16). - Huge cost (13%) associated to generating a surface upon cache miss.
- Huge cost (33%) associated to building the Z-Buffer (
- The ScanLine algorithm cost is obvious:
R_LeadingEdgeR_GenerateSpansR_TrailingEdge
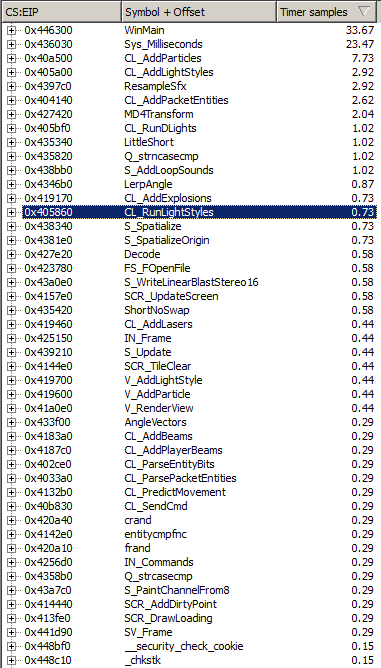
Profiling with Intel's VTune :
A few things noticable:
- 18% dedicated to a common issue with software renderers: The cost to transfer the rendered image from RAM to VRAM (
BitBlit). - 34% dedicated to surface rendition and caching (
D_DrawSurfaces). - 08% dedicated to lerping the vertices for players/enemies animation(
R_AliasPreparePoints).
And even more complete profiling of Quake2 ref_sof with VTune.
{kind=link}
Profiling with AMD Code Analysis:
Kernel Here and ref_sof here.
{kind=link}
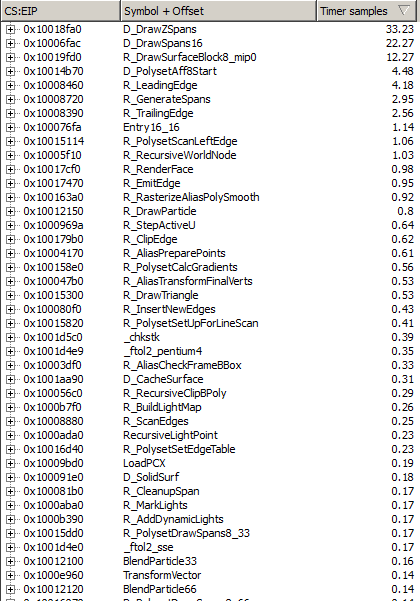{kind=link}
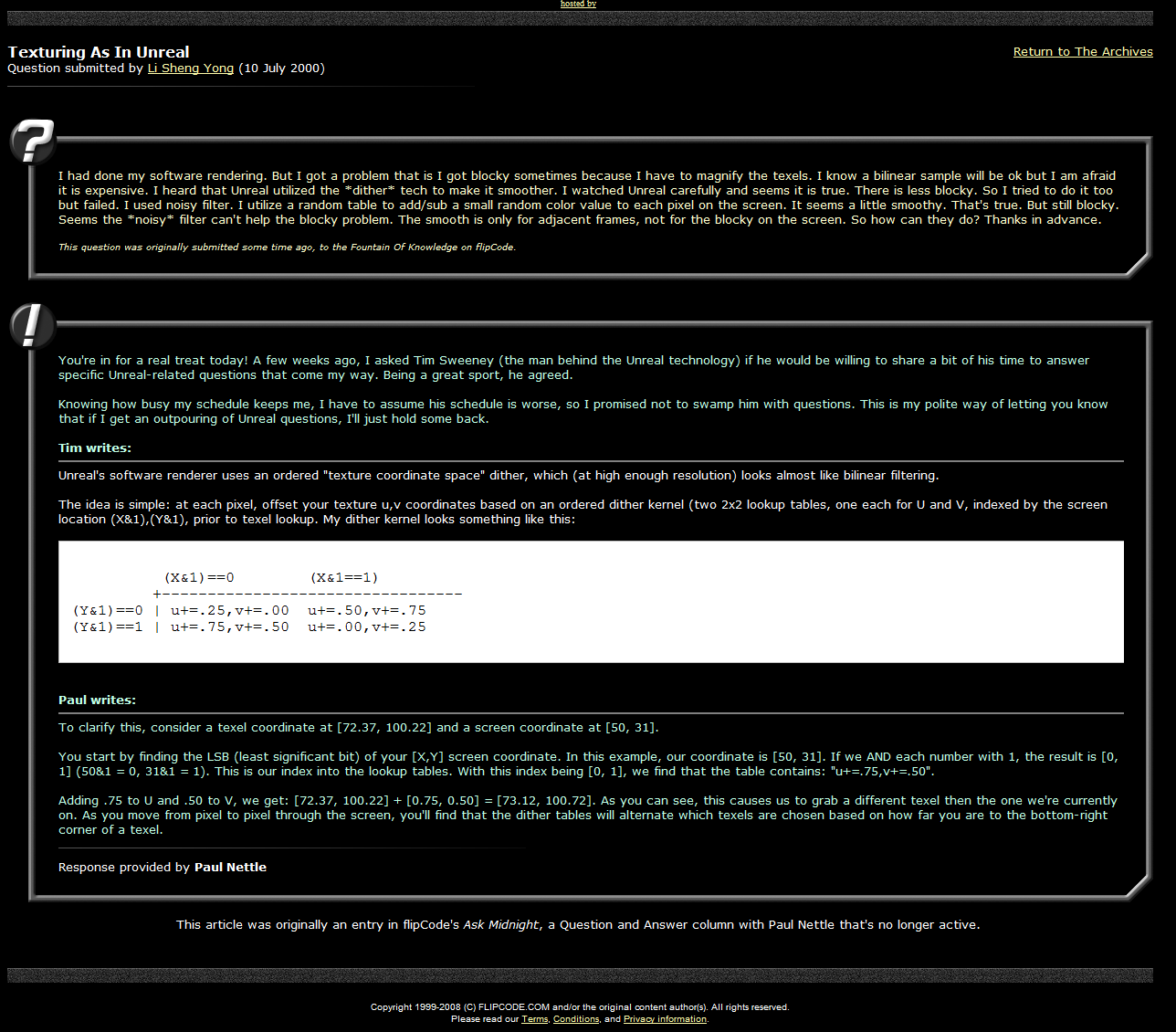
Texture filtering
I have received many questions asking for directions for improving the texture filtering (to bilinear or dithered similar to Unreal (mirror)). If you want to play with this the place to go is D_DrawSpans16 in ref_soft/r_scan.c:
The starting screenspace coordinate (X,Y) are in pspan->u and pspan->v, you also have the width of the span in spancount to you can calculate what is the target screen pixel about to be generated.
As for the texture coordinate: s and t are initialized at the texture original coordinates and increased by (respectively) sstep and tstep to navigate the texture sampling.
Some people such as "Szilard Biro" have had good results applying Unreal I dithering technique:

You cand find the source code of the dithered software renderer in my Quake2 fork on github. The dithering is activated by setting the cvar sw_texfilt to 1.
Original dithering from Unreal 1 software renderer:

{kind=link}